
Når jeg er ude at arbejde med forbedringsteam, og vi kigger på deres data, taler vi jævnligt om, hvordan et enkelt meget højt eller lavt datapunkt skal tolkes. Når der pludselig opstår et afvigende datapunkt, føler teamet ofte trang til at handle og ændre deres arbejdsgange. Men man skal passe på med at handle på et enkelt datapunkt som – trods den høje eller lave værdi – i virkeligheden er udtryk for tilfældig variation.
Jeg har selv været ude i en situation, hvor vi var tæt på at ændre praksis på et hospital på grundlag af et enkelt afvigende datapunkt, som faktisk viste sig at ligge inden for kontrolgrænsen og dermed kun viste tilfældig variation (common cause variation).
Indlæggene skrives af forbedringsagenter, der er ansat hos – eller samarbejder med – Dansk Selskab for Patientsikkerhed.
Formålet med bloggen er at dele erfaringer med og fremme dialog om forbedringsarbejdet.
Højeste mortalitet
Jeg arbejdede med de landsdækkende kliniske databaser i en kvalitetsafdeling på et hospital, og en dag fik vi den nyeste årsopgørelse fra den landsdækkende database for blødende og perforerede ulcus. Det var ikke godt, vi havde en virkelig høj mortalitet for perforerede ulcus, den højeste i regionen, og vi var tæt på de højeste i landet!
Jeg vidste, at direktionen vil gå ind i sagen, og at afdelingsledelsen og kvalitetsafdelingen vil blive bedt om at komme med tiltag med det samme. Men spørgsmålet var selvfølgelig, hvad vi helt præcist kunne udlede af de data? Hvad var årsagen til den høje mortalitet? Var det blot en uheldig periode med fx mere syge patienter og derfor højere mortalitet, eller var der en årsag vi kunne gøre noget ved? Og hvilke tiltag vil så være oplagte?
Ved et tilfælde var jeg ugen inden blevet undervist af overlæge Jacob Anhøj, der er ekspert i SPC (Statistical Process Control), og jeg var blevet meget begejstret for fokus på variation i data. Jeg havde fået nogle statistiske ’spilleregler’, som fortæller, om variationen er tilfældig, eller om der kan forventes at være en særlig forklaring på den.
For at bruge de nye spilleregler på vores data for perforerede ulcus var jeg nødt til at have flere datapunkter. For at vurdere variation er det nødvendigt at se på udviklingen i data over tid. Data på årsbasis er ikke nok. Jeg henvendte mig til NIP-sekretariatet (nu: RKKP) og bad om data på kvartalsniveau (volumen var for lidt til at arbejde med måneds tal) for nogle år tilbage og lavede et kontrolkort (et P-diagram). Grunden til at jeg lavede et kontrolkort og ikke et seriediagram, var at jeg var interesseret i vide, om der var én eller flere kvartaler i det pågældende år (2008), hvor mortaliteten ud fra et statistisk synspunkt var påfaldende høj. For at kunne sige det, havde jeg brug for kontrolgrænser, som seriediagrammet ikke arbejder med.
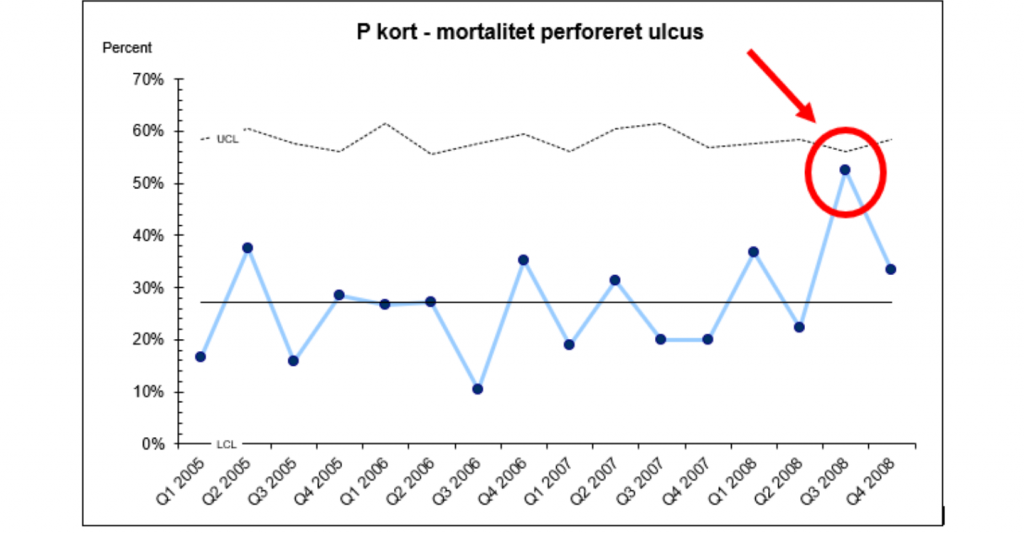
Hvad sagde kontrolkortet?
Kontrolkortet (figur 1) viser, at resultaterne over tid giver udtryk for det man kalder tilfældig variation (common cause variation) (4). Det vil sige, at fordelingen af datapunkterne over tid er sådan, at processen er stabil og forudsigelig. Kortet viser, at der rigtigt nok var en relativ høj mortalitet i Q3 2008, men datapunktet ligger under den øverste kontrolgrænse og viser dermed ’kun’ tilfældig variation. Så selvom gennemsnittet for 2008 ligger højere end de andre år bl.a. på grund af det høje datapunkt i Q3 2008, kan ud fra denne analyse ikke konkluderes, at data viser en forværring af behandlingskvaliteten.
Hvordan skal der handles på disse resultater?
At data ikke viste en forværring af behandlingskvaliteten i 2008, trods den højere mortalitet, var en banebrydende konklusion! En konklusion vi kun kunne nå frem til, fordi vi havde fået adgang til flere historiske data, og fordi vi anvendte SPC, dvs. analyse af data over tid i serie- og kontroldiagrammer.
Hvordan skal der så reageres på disse resultater? I og med at data viste tilfældig variation, var spørgsmålet ikke, om der skulle handles på én eller flere afvigelser i data, man om vi var tilfreds med det niveau, som data viste over hele perioden? Gennemsnittet (kontrol kort arbejder med gennemsnit, seriediagram med median), som figuren viser, lå over perioden 2005-2008 på 28,5% mortalitet for denne patientgruppe. Den nationale standard lå på 20%, så svaret var nej, niveauet var ikke tilfredsstillende! I stedet for at ’brandslukke’, blev vi nødt til at kigge på systemet. Vi måtte analysere de relevante arbejdsgange og udfordringer, der gjorde, at vi lå på det høje niveau. Vil det så i øvrigt sige, at Q3 2008 ikke var værd at undersøge overhovedet? Nej, der kan ligge rigtig meget læring i at undersøge den høje mortalitet for Q3 2008, men selve det ene høje datapunkt giver ikke anledning til at ændre systemet. Det er det ikke-tilfredsstillende gennemsnit, der giver anledning til at ændre systemet.
Undgå tampering
Hvis vi ikke havde lavet analysen og dermed ikke havde fået øje på, at data viste tilfældig variation, havde stemningen omkring denne høje mortalitet været helt anderledes. Og risikoen for, at der skulle handles på de sidste høje mortalitetsdata i 2008, i stedet for at handle på systemet som helhed, havde været stor.
Og her når vi til kernen. W. Edward Demings, der er en af forbedringsvidenskabens fædre kalder det at reagere på et enkelt afvigende målepunkt for ’tampering’. Det er et problem, idet det øger variation og dermed forringer kvaliteten (1,2). Til sammenligning, tænk hvis en praktiserende læge justerede insulinmængden efter hver eneste blodsukkermåling hos en af sine diabetespatienter. Variationen vil blot stige, da patientens blodsukkerniveau over tid også uden insulin vil vise variation i forvejen. Derfor skal det først undersøges hvad for en variation (tilfældig eller ikke-tilfældig), patientens blodsukkermålinger viser, før der kan besluttes hvilken type handling, der er brug for.
Faren lurer
Selvom mit eksempel er fra 2008, mener jeg det fortsat er højaktuelt. I flere sammenhænge, fx i de driftsmålstyringsrapporter, som Region Hovedstaden sender ud til hospitalerne, er fokus primært på overholdelse af den regionale fastsatte standard for de pågældende indikatorer. Rød betyder, at standarden ikke er opnået, grøn betyder at standarden er overholdt. Det betyder, at farven kan skifte fra uge til uge, uden at man kan se om der er reelt er en udvikling i data. Også i det nationale kvalitetsprogram – hvor der ellers er meget fokus på kvalitetsforbedring med udgang i IHI’s (Institute for Healthcare Improvement) redskaber – arbejdes der med afrapportering på årsbasis for de valgte indikatorer, hvilket næppe giver mulighed for at analysere variation over tid. Ved begge eksempler lurer faren for tampering.
Når jeg har været ude på min ugentlige løbetur, og jeg har følt mig i usædvanlig dårlige form netop i denne uge, så ændrer jeg jo ikke på mine rutiner med det samme. Jeg venter lige og ser, hvordan det går i de næste uger. Vi er nødt til at acceptere, at alle processer viser variation over tid. Det gælder også kliniske processer.
Litteratur
- Edwards Deming, On Probability As a Basis For Action. The American Statistician, Vol. 29, No. 4, 1975
- Kompendium I kvalitetsudvikling – rammer og redskaber. Jacob Anhøj, Munksgaard, København, 2015
- The Health Care Data Guide. Learning from data for improvement. Lloyd R. Provost, Sandra K. Murray, Jossey-Bass, San Francisco, 2011
- Solberg, L, G. Mosser and S. McDonald. The Three faces of performance management: Improvement, Accountability and Research. Journal on Quality Improvement, 1997.
Sådan kan ledelsen undgå at reagere uhensigtsmæssigt på data
Hvordan kan ledelsen undgå tampering, altså undgå at reagere uhensigtsmæssig på data ved at reagere på tilfældig variation? Bob Lloyd, direktør for forbedring ved IHI (Institute for Healthcare Improvement), foreslår at ledelsen tilegner sig kompetencer i fire centrale områder, sådan at ledelsen kan ’blink correctly’, når de skal tage beslutninger.
- Ledelsen skal kunne forstå og genkende ’the messiness of improving health care’. Der er sjældent tale om én variabel, der kan skrues op eller ned for, når resultaterne er utilfredsstillende. Oftest er der flere uafhængige variabler, der indbyrdes hænger sammen og influerer på hinanden, og som sammen og hver for sig har en effekt på resultaterne.
- Ledelsen skal være klar over, hvorfor der måles. Er det kvalitetsudvikling, forskning eller for at vise, at en bestemt standard overholdes som i akkreditering (’accountability’) (4). Alle tre formål kan være relevante, men at blande de tre formål, virker kontra-produktiv.
- Ledelsen skal kunne forstå og genkende variation som tilfældig eller ikke-tilfældig variation. Hvis der er tale om tilfældig variation, det vil sige en forudsigelig proces, der viser et niveau i data uden retning, er spørgsmålet om niveauet er godt nok? Hvis der er tale om ikke-tilfældig variation, skal det afgøres, om der er tale om ønsket eller ikke-ønsket variation. Er variationen ønsket, skal årsagerne findes og løsningerne implementeres. Er variationen uønsket, skal årsagerne elimineres.
- Ledelsen skal kunne oversætte data til information. Det vil sige, at ledelsen skal kunne fortolke data og forstå, hvorfor data ser ud, som det ser ud. Kan vi forstå udvikling i data i den ene eller den anden retning? Passer udviklingen af data med vores forventninger? Hvis nej, kan det skyldes vores data, eller skyldes det vores teori? Passer vores data med data fra andre, som arbejder med det samme område?
Kilde: Health Care Executive, MAY/JUNE 2010. Lloyd, R. Helping Leaders Blink Correctly part i and ii

